Did you have any difficulties in implementing your sampling strategy?
If yes, what were these difficulties?
-Yes, the peatlands where I planned on gathering data were either flooded, or snowed over, making finding either Scotch heather or cranberry plants a challenge. The conditions have improved, however, and I returned last weekend to begin collecting data, again.
Was the data that you collected surprising in any way?
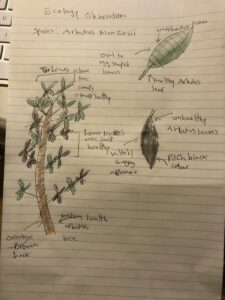
-Not really, however, I only collected one quadrats worth of data. I collected data from within the burn zone. The quadrat only contained Scotch heather (Calluna vulgaris), and it was present with 75% of the cells within a 1m^2 quadrat with 10cm^2 cells.
Do you plan to continue to collect data using the same technique, or do you need to modify your approach? If you will modify your approach, explain briefly how you think your modification will improve your research.
-My basic method of gathering data using the above mentioned quadrat will not change. However, I may change the strings in the quadrat for wires.
Also, after studying experimental design for a few weeks this semester at my own university, I have decided to make some changes to how I will design this study. I have laid my observational study as follows:
The general design format will stratified random sampling, and the the statistical analysis I will use will be based on this design. I will use Jamovi for the analysis.
The burnt area of the bog in the DND lands will constitute one sampling strata, and the unburned area around it, delineated by a square boundary, will constitute the other sampling strata. Each strata contains 10 samples, selected randomly by drawing lots (separately and independently for each strata).
After I drew these lots for each strata, I used a web application (Earthstar GeoInformatics) to figure out where these samples would be found using longitude and latitude. I generated the map shown below:
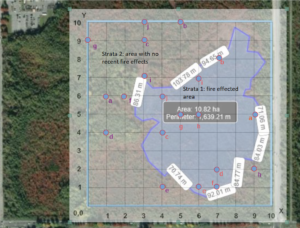
Here are the coordinates for the sample locations, and notes on how I calculated their positions:
Strata 1:
a latitude 49.17356 N longitude 123.10890 W
b 49.17538 123.10638
c 49.17493 123.10764
d 49.17265 123.10890
e 49.17129 123.10700
f 49.17356 123.10827
g 49.17493 123.10954
h 49.17175 123.10385
i 49.17402 123.10764
j 49.17538 123.10764
Strata 2:
a 49.17311 123.10385
b 49.17447 123.10512
c 49.17265 123.10701
d 49.17175 123.10511
e 49.17129 123.10574
f 49.17129 123.10511
g 49.17311 123.10638
h 49.17311 123.10575
i 49.17357 123.10512
j 49.17356 123.10701
I will use my smart phone to find each sample location.
Null hypothesis: there is no correlation between the effects of bog fire, and the presence of Calluna vulgaris and Vaccinium oxycoccos within the DND lands bog.
Alternate hypothesis: there is a correlation between the effects of bog fire and the differences in presence of C. vulgaris and V. oxycoccos, if any such difference can be observed, within the DND lands bog.
The statistical analysis I will use is summarized on this Oregon State University website. I will also be do an analysis to test for correlation between percent presence of both Calluna vulgaris, and Vaccinium oxycoccos within the burnt and unburnt strata. The presence of either species is measured by species present or not present in each cell within the quadrat, each quadrat having 100 x 10cm^2 cells. If a species is present within the cell, this is simply considered a tally of one, for presence within cell. Both heather and cranberry could potentially be counted as present in the same cell, or they could not.
However, I’m not sure yet if Jamovi can already do this, so after doing more data collection tomorrow, I will be exploring what options that software has, and if it doesn’t, I’ll have to decided to either create a module myself, and to simply work through the mathematics myself. I should have a large chunk of my data for strata 1 collected before the weekend, and hopefully have Jamovi figured out by the end of this coming weekend.
Regardless of what modules Jamovi currently has, the sampling design I will use is what I just described, and the analysis will follow the Oregon State web page as my outline for analysis. I’ll go over this in greater detail in a future post.